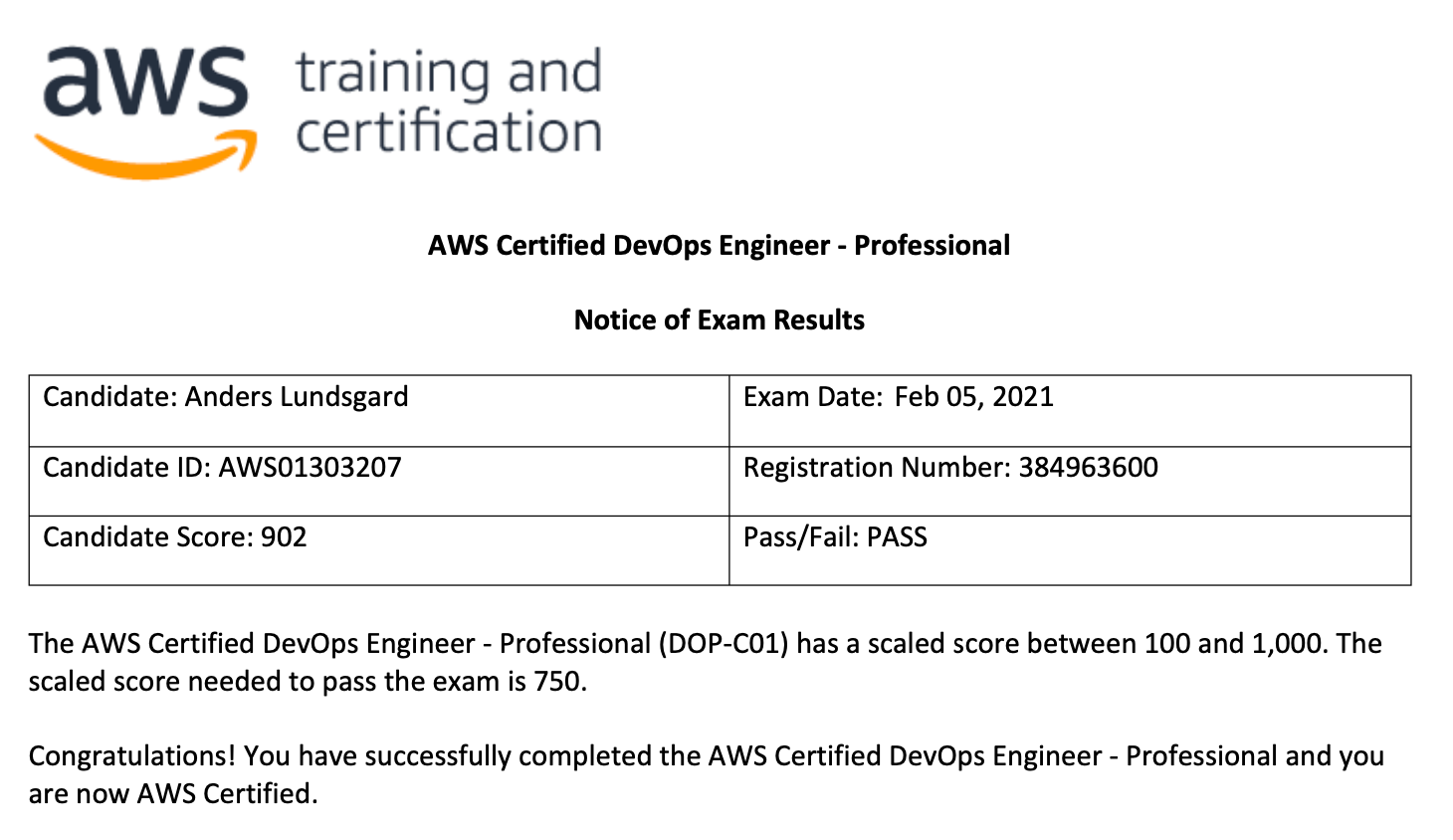
Yesterday I made another milestone in my professional career. I managed to get a pass on the AWS DevOps Engineer Professional Exam.

My last (quite extensive) post was about my PASS of the AWS Solutions Architect Pro (SA Pro) Exam. Since the preparation methods I used was very similar I’ll make this post shorter and explain more of what I actually learned from my studies.
The SA Pro exam is very broad. When reading through the preparation material provided by AWS I got a feeling of that I could more or less can get any question on any AWS Service. Which also was shown to be (almost) true for the SA Pro exam. That is not the case for the DevOps Pro Exam.
All 6 domains, except the one SDLC Automation (described in more detail below), in the DevOps Pro have some overlap to the SA Exams. In other words I could heavily make use of the knowledge i gained during my SA studies.
I mentioned in my last post I’m not a big fan of certifications. In the way that a certificate “proofs” your knowledge, my opinion has not changed. You really should NOT hire me just for having these badges. Although the “requirements” to get a PASS claims that you need extensive experience working with AWS, I still not believe that is the case.
However, since I anyway continue to study for certifications, there is one thing with these studies that for me make the effort valuable…
– I learn things I probably should not have learned in my daily work!
…and these learnings have shown to be valuable in my daily work.
SDLC Automaiton
I got one big sad learning from my AWS DevOps Pro journey. The AWS Code* (CodeCommit, CodePipeline, …) is really not services suited for medium or larger organizations. There is one big advantage with these services:
They are all serverless and mostly well integrated with the rest of the AWS services ecosystem. IAM integration and so on.
…but there the advantages ends :-(.
Disadvantage #1 – Pipeline versioning
You can not version the pipeline (CodePipeline, pipeline.yml) in the same repository as the code it automates. Of course you can put the pipeline.yml file in the repository, but an update of that file will not update the actual pipeline itself. In my private AWS Organization I had to do a hack with an home made lambda that made that possible.
Disadvantage #2 – Pipeline progress usability
Having used GitLab and GitLab CI for many years, I’ve been used to the (almost) instant and good overview of the pipeline progress visualization. With Code- Commit/Pipeline/Build/Deploy I sometimes end up in 10 clicks just to get the logs for a pipeline execution. Not developer friendly at all.
Disadvantage #3 – Amount of code needed
Having experience from GitLab CI (and a bit of GitHub Actions and BitBucket Pipelines) writing tiny pipeline.yml files for automation. Then start define CodePipeline definitions is not a pleasant experience. I estimate CodePipeline definitions to have about three times more yml-code compared to the more competitive alternatives.
Disadvantage #4 – Code collaboration capabilties
CodeCommit is based on Git which is good. But (currently) there are zero capabilities for code collaboration. When you got used to search through all code on github.com you really can’t live without the global search feature to find code among your code repositories. – Come on CodeCommit team!
Summary
To end in a positive way I must really say that my learnings from the AWS CloudWatch service has been VERY pleasant. Of course CloudWatch and the teams behind the service was released 10+ years ago. The Code*-teams are quite new and hopefully will also start to listen to customer feedback.
…and my result: